hotsub
CLI tool to run a batch jobs with ETL/ExTL framework on AWS or other cloud services.
This page describes how
hotsubworks on cloud services, such as AWS.
Example
As it’s described in Getting Started, you can run a script on cloud instances by run command.
% hotsub run \
--script hello.sh \
--tasks hello.csv \
--verbose
it will show following logs
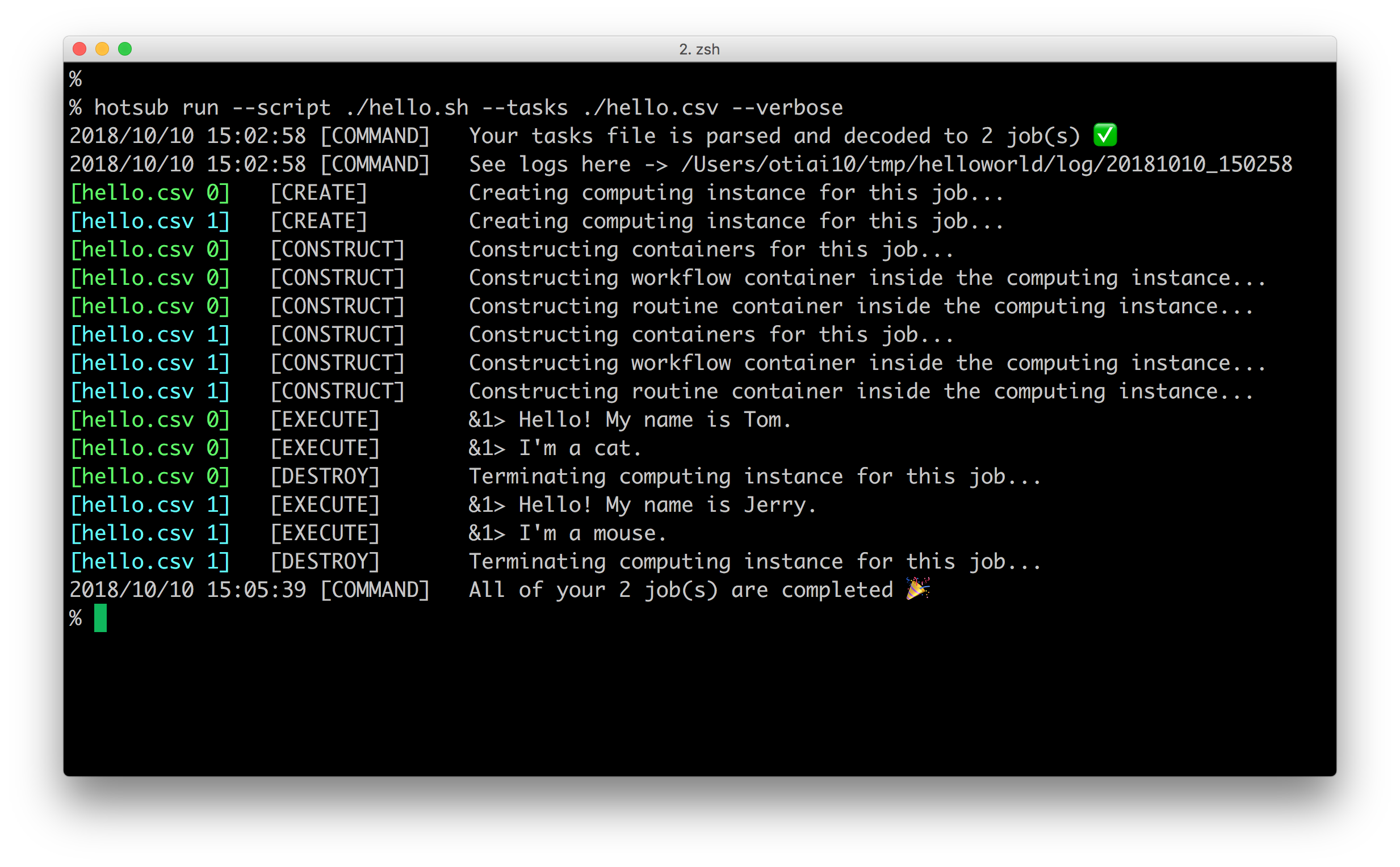
Here explains what each step does and how it works.
Lifecycle Overview
Basic lifecycle of hotsub execution is constructed by following steps.
- Command parsing
[CREATE]*: starting up VMs on cloud services (AWS EC2, by default)[CONSTRUCT]*: starting up Docker containers on the VMs[FETCH]*: downloading input files specified intasksCSV file[EXECUTE]*: processing specifiedscriptfile on the Docker containers[PUSH]*: uploading output files to the URL specified intasksCSV file[DESTROY]*: terminating VM instances no longer used

[CREATE]
[CREATE] step creates VM instances on cloud services, which is specified with --provider option (aws by default).
The number of VM instances are defined by the rows of task CSV file, it means when the following CSV is given
--env NAME, --env AGE, --env NATIONALITY
Hiromu, 32, Japan
Tainaka, 17, Japan
this CSV will create 2 VM instances because 2 samples are specified excepting for header row.
hotsub uses docker-machine for [CREATE] step, this is why you need to install docker-machine as one of prerequisites.
[CONSTRUCT]
After creating VM instances, [CONSTRUCT] step sets up Docker containers inside the VMs.
By using separated Docker containers inside 1 VM instance, hotsub enables to run **any script** on VM instances **without caring** about neither downloading input files nor uploading output files.
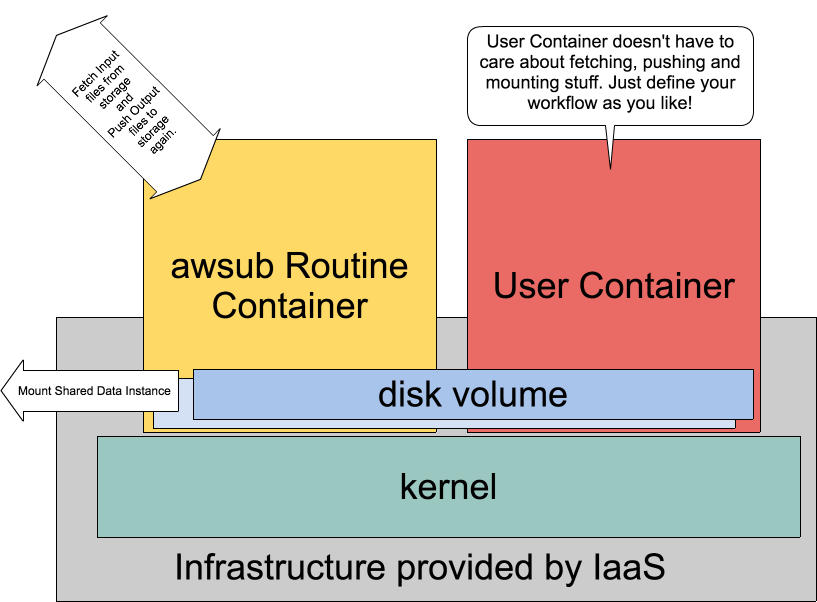
[FETCH]
The containers are still empty, then [FETCH] step will download input files assigned to each VM instance.
For example, when following CSV is given (1 column CSV to make it simple ;)
--input BAMFILE
s3://my-bucket/path/case_XXX/sorted.bam
s3://my-bucket/path/case_ZZZ/sorted.bam
As described before [CREATE] step creates 2 VM instances for case_XXX and case_ZZZ, and [FETCH] step downloads those files from S3 (in this example) and locate them in specific file path in each VM.
The file locations can be accessed as env variables represented by column names, e.g. env var $BAMFILE specifies the location of downloaded sorted.bam in each VM.
[EXECUTE]
Thus your script given with --script does not need to care about downloading input files and can just access those files with environment variables, like this
bwa mem \
-t 2 -T 0 \
${REFERENCE}/${REFERENCE_FILE} \
${FASTQ_1} ${FASTQ_2} \
> ${DEST}/result.sam
# From https://github.com/otiai10/hotsub/tree/master/examples/BWA
The only thing this script should care about is to place output files at directory specified with --output-recursive, all the files placed that directory are going to be uploaded by the next step: [PUSH]
[PUSH]
Once [EXECUTE] step succeeded, [PUSH] step will upload the files located under the directories specified with the column name of --output-recursive to the location specified by the values of columns.
For example,
--output-recursive OUTDIR
s3://my-bucket/path/case_XXX/out
s3://my-bucket/path/case_ZZZ/out
if [EXECUTE] step any files under the location $OUTDIR, able to access as env var same as --input, that will be pushed to specified URLs from each VM.
[DESTROY]
Even if [EXECUTE] succeeded or failed, because it’s not good idea to keep the instance alive, [DESTROY] step will be called and terminates all the VM instances to keep your cloud account NOT CHARGED.